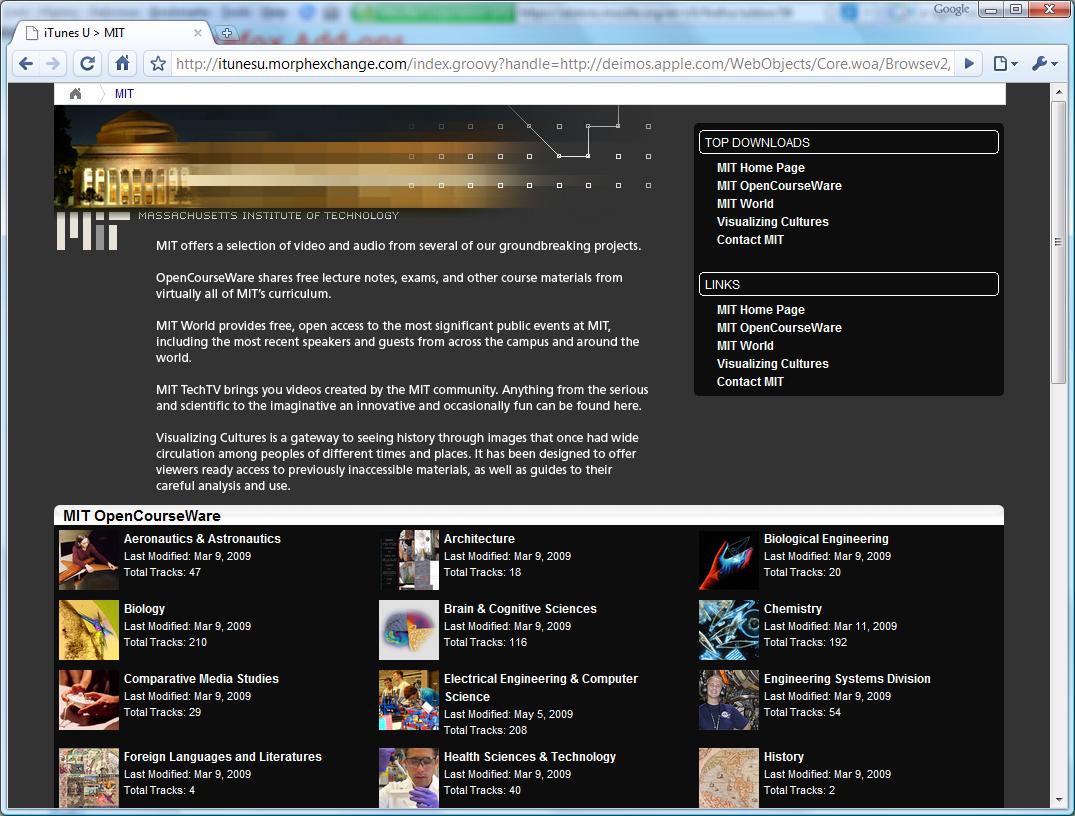
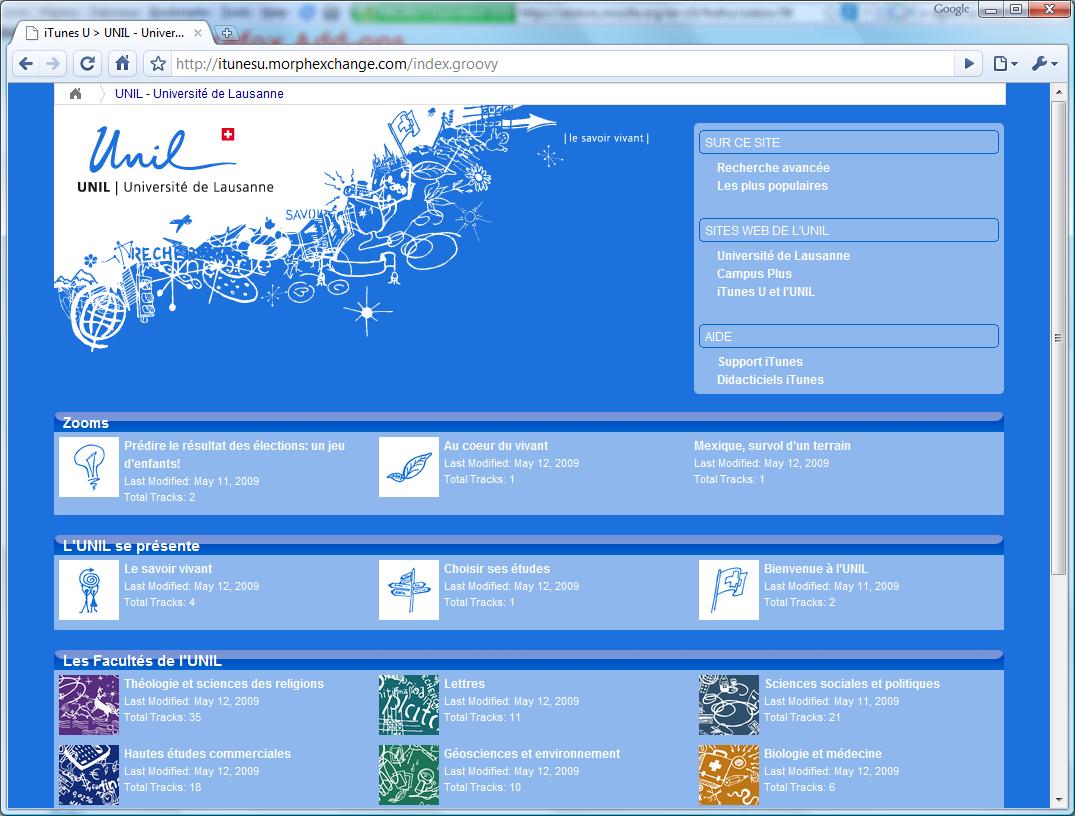
Updated version of the script
On some pages the location-bar information is available (third-level pages), but 1st and 2nd level pages do not have a location-bar. Even in iTunes it has been removed in favor of a location-bar managed by iTunes. I suppose this is done in order to make use of a cached version of the page and speed up loading. Having no location-bar at 2nd level pages is an awkward design choice from Apple. Therefore location-bar has to be managed by the script and 3th level pages need also to be re-adapted to be displayed correctly.
Fixed version can be tested here: http://1.latest.unil-podcast.appspot.com/index.groovy?handle=[itunesU url]
the new source files are available here:
complete source code at github http://github.com/bfritscher/www-itunesu
index_fixed.groovy – new version with navigation fixed
proxy.groovy – proxy class because iTunes checks user-agent to link to some video files behind a redirect.
The problem
More and more universities publish courses as podcasts on iTunesU and neglect to give a direct access to their content. This hinders sharing of knowledge, because of the obligatory Apple’s iTunes application needed to access iTunesU.
The solution
Emulating the iTunes client: the script can be tested at
http://www2.unil.ch/itunesu/index.groovy?handle=[itunesU url]
It only needs the url which would open in iTunes and converts it to a displayable webpage.
For example for mit.edu: http://deimos.apple.com/WebObjects/Core.woa/Browsev2/mit.edu
http://www2.unil.ch/itunesu/index.groovy?handle=http://deimos.apple.com/WebObjects/Core.woa/Browsev2/mit.edu
Source download
index.groovy version 1 iTunesU xml to html groovy script
Why groovy?
Having experience with Java and Grails development using Groovy especially due to its powerful closures, xml navigation and html building was a obvious choice. Also this project started as a Google AppEngine prototype, but hit the no-user-agent change limitation.
Limitations
Of the three types of layout used in iTunes U only the two column standard university page view and detailed course view (track list) are supported. The iTunes main site listing and main page three column layout is not supported.
Solution explained
iTunes uses a custom xml page to receive and render its content. This file can be access when switching the user-agent to “iTunesâ€.
Switching user agent is easy under Firefox with the user-agent switcher add-on
Part of the xml file
<FontStyleSet setName="basic22" normalStyle="helvetica22"
linkStyle="link" linkPressedStyle="linkPressed" linkRolloverStyle="linkRollover" />
<FontStyleSet setName="normal40" normalStyle="lucida40"
linkStyle="link" linkPressedStyle="linkPressed" linkRolloverStyle="linkRollover" />
<FontStyleSet setName="normal40Bold" normalStyle="lucida40Bold"
linkStyle="link" linkPressedStyle="linkPressed" linkRolloverStyle="linkRollover" />
<MatrixView rightInset="0" bottomInset="0" leftInset="0"
topInset="0" rowFormat="100%,*" viewName="Form">
<View rightInset="0" bottomInset="0" leftInset="0" topInset="0"
minWidth="948" minHeight="400">
<VBoxView>
<!-- Layer 1 = Banner Image -->
<!-- BEGIN ReplaceableImageXMLView -->
<View alt="" height="400" width="600">
<PictureView proportional="1" verticalAlignment="top"
shouldBeVisible="true" shadowHeight="0"
alt="MIT offers a selection of video and audio from several of our groundbreaking projects: MIT OpenCourseWare, MIT World, MIT TechTV, and Visualizing Cultures."
shadowWidth="0" height="400" width="600"
url="http://deimos3.apple.com/indigo//2c/c5/f3/93/2cc5f393018ecb9b1a3991063e10376b093cd1918f43b3847af32a8a9ba35103-1502158938.jpg"
addShadowSizes="false" />
</View>
<!-- END ReplaceableImageXMLView -->
</VBoxView>
<VBoxView>
<!-- Layer 2 = link box area -->
<MatrixView leftInset="0" rightInset="0" topInset="25"
columnFormat="65%,25,35%">
<!--
This ensures we leave enough room for the banner image in the 3
column view
-->
<View minHeight="400" />
<View />
<VBoxView rightInset="25" bottomInset="0" leftInset="0"
topInset="0">
<VBoxView>
<VBoxView leftInset="0" rightInset="0" topInset="0"
bottomInset="0">
<!-- BEGIN description box-->
<!-- END description box-->
<!-- START ListBoxStack -->
<View>
<FontStyle name="outlineTitleFontStyle" color="ffffff" />
<FontStyle name="outlineTextFontStyle" color="ffffff" />
<!-- BEGIN RoundedBox -->
<View rightInset="0" bottomInset="0" leftInset="0"
topInset="0">
<Test value="7.0.0" comparison="greater or equal"
property="iTunes version">
<!-- BEGIN MaskedView -->
<View rightInset="0" bottomInset="0" leftInset="0"
topInset="0">
<PictureButtonView rightInset="0" topInset="0"
bottomInset="0" leftInset="0" alt="" color="rgba(0,0,0,0.75)"
mask="http://deimos3.apple.com/rsrc/Images/masks/rounded_box.png"
cap="4" />
</View>
</Test>
</View>
</View>
</VBoxView>
</VBoxView>
</VBoxView>
</MatrixView>
</VBoxView>
</View>
</MatrixView>
The xml file is quite verbose and it takes some time to identify the interesting content.
The hard part of this project was to identify the right way to identify and select the wanted data from the xml tree.
Following are code snippets of the source file with their most important or interesting aspects explained.
First task of the script is to retrieve the xml page by settings the right user-agent [3] and then use the powerful groovy xml parser api [13] to have an easily navigable xml object.
def xml
def conn = new URL(handle).openConnection()
conn.setRequestProperty ( "User-Agent", "iTunes/8.1" )
def putBackTogether = new StringBuffer()
def r = new InputStreamReader ( conn.getInputStream(), "UTF-8" )
char [ ] cb = new char [ 2048 ]
int amtRead = r.read ( cb )
while ( amtRead > 0 ) {
putBackTogether.append ( cb, 0, amtRead )
amtRead = r.read ( cb )
}
xml = putBackTogether.toString()
xml = new XmlSlurper().parseText(xml)
To work around default namespace bugs when recreating a xml string from an xml object the Markupbuilder has to be set to the apple namespace[6].
import groovy.xml.StreamingMarkupBuilder
def getXml(item){
def outputBuilder = new StreamingMarkupBuilder()
outputBuilder.encoding = "UTF-8"
String result = outputBuilder.bind{
mkp.declareNamespace("":"http://www.apple.com/itms/")
mkp.yield item
}
}
Example of the powerful way to generate html code with the groovy MarkupBuilder.
import groovy.xml.StreamingMarkupBuilder
html.html(xmlns:"http://www.w3.org/1999/xhtml",lang:"en",'xml:lang':"en") {
head {
title xml.Path.PathElement.collect{it.'@displayName'}.join(" > ")
meta('http-equiv':"X-UA-Compatible", content:"IE=8")
meta('http-equiv':"content-type",content:"application/xhtml+xml; charset=UTF-8")
//...
Identifying the type of layout the xml file is meant to build is done by looking at a reflection attribute from the first image found in the file.
def topimg = xml.'**'.find{ it.name() == "PictureView"}
def reflect = topimg?.'@reflection'==1 //true = course page
Getting page colors from FontStyle tags
def titleFontStyle = xml.'**'.find{it.name() == "FontStyle" && it.'@name' == "normalTitleFontStyle"}?.'@color'
if(titleFontStyle == null){
titleFontStyle = xml.'**'.find{it.name() == "FontStyle" && it.'@name' == "outlineTitleFontStyle"}?.'@color'
}
Some more examples of the groovy MarkupBuilder: especially interesting is the mkp.yieldUnescaped [10] method to allow usage of html otherwise automatically converted symbols like &.
body(style:"background: #${xml.'*'.find{ it.'@backColor' != ''}.'@backColor'}"){
div(class:"container"){
div(class:"span-24 last nav"){
def list = xml.Path.PathElement
def last = list.size()-1
list.eachWithIndex{ pe,i ->
if(i == 0){
a(class:"first",href:"index.groovy?handle=${pe.text().trim()}"){
span(){
mkp.yieldUnescaped " "
}
}
}else{
a(class:"${i == last ? 'last' : ''}",href:"index.groovy?handle=${pe.text().trim()}", pe.'@displayName')
}
}
}
}
}
Being able to identify the right element is sometimes a bit tricky, especially that not all pages seem to follow the same structure rules.
div(class:"description"){
xml.ScrollView.View.MatrixView.View?.'**'.find{it?.name()== "VBoxView" && it?.parent()?.name()== "VBoxView" && it?.parent()?.parent()?.name()== "VBoxView" && it?.parent()?.parent()?.parent()?.name()== "VBoxView"}?.'*'.findAll{ it?.name() == "TextView"}.each{ text -> p text }
mkp.yieldUnescaped " "
}
Usage of the xmlwise library[15] to parse the standard plist part of the xml containing the track list .
import xmlwise.*
div(class:"span-24 last tracklist"){
table(cellspacing:"1", class:"tablesorter"){
thead{
tr{
th ""
th "Name"
th "Time"
th "Artist"
th "Release Date"
th ""
}
}
tbody{
def plist = Plist.fromXml(getXml(xml.TrackList.plist))
plist.items.eachWithIndex{ track, i ->
int seconds = (track["duration"] /1000)
int minutes = seconds % 3600
int hours = (seconds - minutes) / 3600
seconds = minutes % 60
minutes = (minutes - seconds) / 60
tr(class:i % 2 == 0 ? "even" : "odd"){
td track["rank"]
td track["songName"]
td ((hours > 0 ? String.format("%02d",hours) + ":" : "")+ String.format("%02d",minutes) + ":" + String.format("%02d",seconds))
td track["artistName"]
td track["releaseDate"][0..9]
td{
a(href:track["previewURL"],rel:"lightbox[set 480 380]",title:track["songName"], "view")
mkp.yieldUnescaped(" ")
a(href:track["previewURL"],title:track["songName"], "download")
}
}
}
}
}
}
Resources used for html design