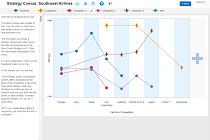
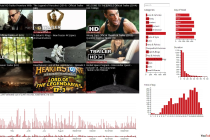
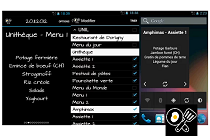
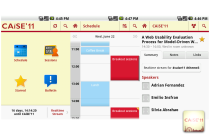
To Blog TechnoBabel: Discoveries from the Virtual World Blog HEC 4 ALL Wiki vers les liens de cours & résumés HEC 4 ALL Group Assigner Organize participants into groups over multiple rounds Group Assigner Projects BM Evolution: Valve Corporation Business Model Evolution: Valve Corporation Use Case. Site presenting case from my phd. BM Evolution: Valve Corporation PhD Prototypes Prototypes done for my research, web technologies, D3.js AngularJS, Knockout, jQuery PhD Prototypes USA 2014, Travel Report USA 2014, Travel Report, code 2014, google maps, AngularJS USA 2014, Travel Report ColorVote.ch Anonymous polling for large classrooms, code 2013, AngularJS, Nodejs, MongoDB ColorVote.ch StrategyCanvas.org Realtime collaboration on Blue Ocean’s StrategyCanvas, code 2013, AngularJS, Grails StrategyCanvas.org YouTube History Visualization Personal YouTube watch history visualization with dc.js and crossfilter YouTube History Visualization CampusCard History Visualization Personal CampusCard expenses history visualization with dc.js and crossfilter CampusCard History Visualization Campus Food Lausanne Android Android application for menus of UNIL and EPFL cafeterias, code 2012 Campus Food Lausanne Android BlueSkies.ch Website & admin code 2011, cakephp, css media queries BlueSkies.ch CAiSE’11 Android App A conference application for CAiSE’11.This is a fork of the Google I/O 2011 conference application modified for CAiSE’11. CAiSE’11 Android App ECIS2011 Android App A conference application for ECIS2011.This is a fork of the Google I/O 2011 conference application modified for ECIS2011 ECIS2011 Android App GetVelo Android App Obtenez de l’information en temps réel sur la disponibilité des vélos pour chaque station des services velopass / suisseroule / campusroule. GetVelo Android App Samaritains Nyon Intranet Intranet for member management, design & code 2010, cakephp Samaritains Nyon Intranet Web Explorer Website which allows students to create HTML/CSS/Javascript pages from within the browser. (behind university login) Web Explorer Velopass Bike Availability Parsing official website to generate uniform access to data, 2009, python, with cgaspoz Velopass Bike Availability SQL Explorer Website which allows students to train SQL queries. Can also evaluate assignments with moodle SCORM. php, postgresql SQL Explorer BM|DESIGN|ER Business Model Innovation 2009, design & code, Grails, javascript BM|DESIGN|ER Samaritains Nyon Samaritains de Nyon website 2005, design & code, php Samaritains Nyon Thérapie Cabinet de Naturothérapie website, design & code Thérapie Archive HBC Nyon HandBall Club Nyon website & intranet 2007, design & code, cakephp HBC Nyon Labels Générateur d’étiquettes Labels PanMan FIFA WORLD CUP 2006 panini sticker manager PanMan Dojo Dojo javascript toolkit tutorials (old) Dojo Rounded Corners Ajax Rounded Corners Generator, deprecated: use css border-radius: XYpx Rounded Corners Shopalot E-commerce Drag and Drop UI, dojo Demo 2007 Shopalot